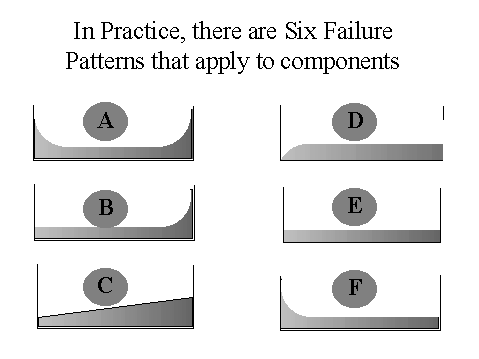
One of the more startling of these is some of the myths and legends out there surrounding pattern E, random or constant failure, and pattern F, infant mortality.
Myth 1: It still represents the vast majority of failures!
This was one of the ah-ha moments of the RCM study. The fact that 64% of failures were in teh early stages of life.Infant mortality is caused by a range of factors. And here we have to remember where this information actually comes from...
When it was produced it came from the airlines industry, and painted a picture of a time a long time ago (In a galaxy far, far away)
In that time it was customary to take stuff out, pull it to bits, put it all back together again and reinstall it.
Issues such as design failures or quality issues are a major part of why assets fail early, justifying the need for pre-service inspections and NDT, but so too were human errors.
Failures in replacement, rebuild, installation and so on. You know the type - suddenly you have a vast number of spares when you reassemble it.
Today, however, this is less commonplace. Today companies are just as likely to use some form of condition based approach, (to manage their assets in general) or a fix on fail approach where it is viable to do so.
In my experience the number of burn in failures, aside from a few electronic components, is markedly lower than the 64% quoted by Nowlan and Heap. This analysis of Submarine data actually supports that. Even though this was nowhere near as rigorous as the original N&H report - it is still a good indication.
And if it points to anything... it points to Human Error (a La HEART type techniques) and reductions in over maintenance.
Is it still significant? Yup! Is it still the majority of the failure types you would have? Probably... but the percentages would be different in your industry and company than those of Nowlan and Heap nearly thirty years ago.
Human Error is emerging more and more as the rock sticking out of the receding tides of failure.
Myth 2: CBM is the best way to manage Pattern F
This is a wonderful scam for those wanting to hawk condition monitoring services. The reality is unfortunately never as simple as catch phrases and easy correllations.
It is generally used in conjunction with the myth above. Meaning - a) the boogey man is still out there, and b) you need lots of CBM to manage it.
There are two holes in this argument...
CBM is only, (ONLY) useful for predicting the onset of failure if the following is present: (It also has proactive uses, but we have posted on that recently)
1) A potential failure condition
2) A P-F interval that is reasonably consistent. (Keep that one in mind, it often gets overlooked)
3) A P-F interval that is large enough to actually do something useful. (To reduce costs or risk etcetera)
4) It actually reduces the whole of life costs, or reduces the level of risk to a factor that can be considered to be tolerable.
That's it. Is it useful for random failures? Definitely. But it is not the only task type. Detective maintenance is also very (VERY) useful for random hidden failures.
This ties into the second problem with this argument...
If most of them are failing in the early stages, so much so that there is a high likelihood of early failure - how can we be sure that the remainder are really random? And how many of the items that do remain are there anyway? Is this a significant figure?
So if you could eliminate the early life failure, we do not know which failure type the failures would end up as. Most of them die early remember!
As pointed out by Resnikov in his great work on mathematics and RCM, this is the fundamental reason why bathtub curves are so highly unlikely to exist at all!!
In summary
The way to deal with pattern F is through elimination of the causes of early life failure, not through CBM. Period! This means attending to human error, design issues, quality issues and over maintenance. (The last probably being the most prevalent)
CBM is applicable to random failures to detect the onset of failure, but only when the 4 criteria outlined above have been met. As with any type of failure mode! (But your wisest bet is (of course) to eliminate the early life failure first. Then it becomes one of the other failure types)
Sadly, it is almost always the case that people making grand statements like this, without more than theory or guessing to back them up, are doing so to sell something else totally. And not for the intellectual rigor of the reliability of the plants they are working on.
Even more sadly, it is often the case that they don't fully understand the theme also...
No comments:
Post a Comment